Anoop MauryaOllama-OCR: Now Available as a Python Package!Stuck behind a paywall? Read for Free!Dec 2, 202417Dec 2, 202417
InTDS ArchivebyDr. Leon EversbergImproved RAG Document Processing With MarkdownHow to read and convert PDFs to Markdown for better RAG results with LLMsNov 19, 202412Nov 19, 202412
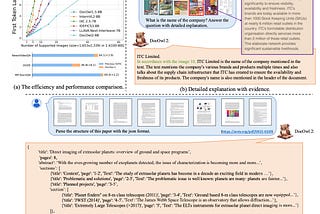
InTowards AIbyFlorian JuneLet AI Instantly Parse Heavy Documents: The Magic of MPLUG-DOCOWL2’s Efficient CompressionToday, let’s take a look at one of the latest developments in PDF Parsing and Document Intelligence.Nov 13, 20242Nov 13, 20242
InTowards AIbyFlorian JuneDemystifying PDF Parsing 05: Unifying Separate Tasks into a Small ModelMechanics, Code, Insights on GOT, DLAFormer, and UNITSep 19, 20243Sep 19, 20243
InAI AdvancesbyRichardson GundeThe PDF Extraction Revolution: Why PymuPDF4llm is Your New Best Friend (and LlamaParse is Crying)Hey there, data-loving friends! Ready for some serious AI magic? Picture this: you’re knee-deep in PDFs, trying to extract information for…Oct 31, 202429Oct 31, 202429
Agent IssueLlama 3.2-Vision for High-Precision OCR with OllamaWith the new Llama 3.2 release, Meta seriously leveled up here — now you’ve got vision models (11B and 90B) that don’t just read text but…Oct 31, 20241Oct 31, 20241
InPython in Plain EnglishbyAnoop MauryaWhy PyMuPDF4LLM is the Best Tool for Extracting Data from PDFs (Even if You Didn’t Know You Needed…Stuck behind a paywall? Read for Free!Oct 18, 202420Oct 18, 202420
PankajUnlock the Power of PyMuPDF4LLM: A Game-Changer for PDF Extraction and AI WorkflowsEfficiently Convert PDFs to Structured Data for Large Language Models and Retrieval-Augmented Generation SystemsOct 15, 20244Oct 15, 20244
Suman SourabhThis is How I Convert PDF to MarkdownBetter than any online tool out thereSep 7, 20245Sep 7, 20245
InAI AdvancesbyFlorian JuneDemystifying PDF Parsing 06: Representative Industry SolutionsThis is the sixth article in our series. In this article, we explore how PDF parsing is performed within the well-known and popular RAG…Oct 9, 20246Oct 9, 20246
InTowards AIbyTarun SinghAI and LLM for Document Extraction: Simplifying Complex Formats with EaseAI and LLMs for Document Extraction: Simplifying Complex Formats with EaseSep 27, 20247Sep 27, 20247
InAI AdvancesbyFlorian JuneKotaemon Unveiled: Innovations in RAG Framework for Document QAPDF Parsing, GraphRAG, Agent-Based Reasoning, and InsightsSep 13, 20244Sep 13, 20244
InLevel Up CodingbyLan ChuWorking with PDFs: The best tools for extracting text, tables and imagesWith PyPDF, Camelot, Tabular, Adobe APIApr 30, 20248Apr 30, 20248
InGenerative AIbyFabio MatricardiThe Tiny JSONist — meet AI NuExtractLooks like a bad words, but it is not. This is the best SML to take a text IN and give you a structured JSON OUT. Wanna know more?Aug 11, 20241Aug 11, 20241
InAI AdvancesbyFlorian JuneDemystifying PDF Parsing 04: OCR-Free Large Multimodal Model-Based MethodPrinciples, Insights and ThoughtsJul 1, 20243Jul 1, 20243
Florian JuneUnveiling PDF Parsing: How to extract formulas from scientific pdf papersThis article is a supplement to Advanced RAG 02: Unveiling PDF Parsing.Feb 15, 20242Feb 15, 20242
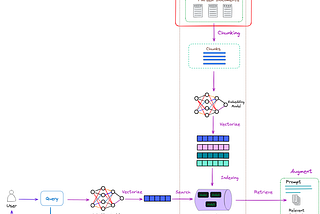
InTowards AIbyFlorian JuneAdvanced RAG 02: Unveiling PDF ParsingIncluding key points, diagrams, and codeFeb 2, 202422Feb 2, 202422
InTDS ArchivebyNoah HaglundDesigning and Deploying a Machine Learning Python Application (Part 2)You don’t have to be Atlas to get your model into the cloudFeb 24, 2024Feb 24, 2024
InTDS ArchivebyNoah HaglundTraining and Deploying a Custom Detectron2 Model for Object Detection using PDF Documents (Part 1…Making your machine learn how to see PDFs like a humanNov 29, 2023Nov 29, 2023